前言
目前的运维行业有个趋势就是云原生,可以看到的趋势就是像是容器和无服务计算开始慢慢推行。结合实际工作上有一个趋势那就是上云,为了能够更好的了解其基础我打算从容器入手,像是工作中用到的k8s和docker之类的,这次打算好好学一学,同时呢也报名了CKA和CKS的考试,这里记录一下所学的笔记和实际遇到的问题。
这篇文章是关于CKA考试中使用到的runtime docker的基础部分。
促成DevOps落地的容器技术
DevOps是一种重视软件开发人员(Dev)和运维技术人员(Ops)之间的沟通合作的文化,它透过自动化“软件交付”和“架构变更”的流程,使得构建、测试、发布软件能够更加快捷、频繁和可靠。
DevOps不只是一个技术上的问题、更多是一个流程、管理、乃至公司架构的问题;是为了解决“时间”与“质量”而产生的一种交付文化、流程和交付方式的统称,DevOps期望通过消除“等待”的方式来实现更快速、更高质量的交付
DevOps不只是简单的自动化流程,更多的是开发方式,开发流程的变革,但是由于团队架构、工具生态和基础架构等原因,使得DevOps的理念难以有范式的操作流程可以参考,更多的是在某些特定场景或交付流程中实现了部分的最佳实践。
直到现代应用容器技术的推出,才让DevOps终于有了范式化的路径;而微服务的流行更是基于容器技术,为DevOps落地和实践添了一把火。
微服务简介
我们来说说微服务的优缺点。
优点
- 将大型的单体服务系统拆分成多个微服务,解决了应用复杂性的问题
- 每个服务都有专门的团队负责,可使用最合适的技术进行实现,使得架构演进更加简单
- 微服务之间的耦合度低,可以独立更新
- 各个微服务可以独立部署,也可以根据业务的特征动态调整规模
缺点
- 对既有的应用进行分布式改造依赖相当程度的技术能力
- 拆分后各程序的指责不同,标准化的工作将变得困难
- 各服务的通信成本(延迟)远大于单体内部组件的通信
- 管理多个组件或组件拓扑成为微服务的头等要务
- 数据库的设计和业务规划成为微服务中的难点
容器和容器编排技术定义了新的交付方式,能解决上面的缺点中的大部分问题!
我们来设想一个场景,比如说你所在的一家公司是提供餐饮服务的订餐服务软件的软件公司。你的客户有A、B、C、D四家公司。
- 其中A客户系统需要在他们本地部署,使用的是CentOS7的操作系统。
- B客户需要在他们云上部署,使用的是openSUSE Leap的操作系统。
- C客户需要在他们的PaaS平台上部署,使用的是OpenShift。
- D客户需要在他们的本地部署,使用的是Ubuntu 16.04的操作系统。
像是一个服务后端要去这么多不一样的操作系统上部署,实际上是有不同的依赖关系的。如果每个平台都要去开发对应的后台这个开发成本以及维护成本是相当高的,但是有了容器之后就可以做到一次构建到处运行,可以在客户的系统上部署好容器,然后使用容器去运行和编排服务。
什么是容器?
- 经典容器指的是操作系统用户(Userspace)虚拟化技术,为应用进程及其运行环境提供隔离的沙箱(Sandbox)
- LXC时代的容器技术更像是“虚拟机”,可被称为操作系统容器
- Docker时代的容器技术是应用容器,仅用于运行单个应用的进程以及子进程
Linux容器技术发展简史
- 2006年,Google Process Containers
- 限制进程可用的资源(CPU、内存、磁盘IO和网络):
- 2007年更名为ControlGroups,简称CGroups,合并到Linux 2.6.24内核版本中
- 2008年出现的lxc技术代表着Linux系统上第一个最为完整的容器管理器出现
- Linux namespace
- mount名称空间是始于Linux2.4.19版本的第一个内核名称空间技术
- UTS和IPC两个名称空间与Linux2.6.19版本引入
- 2.6.23引入了User名称空间,但是直到3.8版本才完成
- 2.6.24引入CGroups,PID名称空间和Network名称空间,但直到2.6.29,Network名称空间才真正完成
- LXC全称为Linux Container,它是一个工具集,通过将CGroups的系统资源管理能力和Namespace的视图管理能力结合在一起,实现了Linux Native的容器以及容器管理接口
- 2013年,由dotCloud创造性地发明了容器镜像技术,并使用了应用容器技术,使得其维护的Docker容器项目名声大噪,极大地推动力容器技术的发展进程
- 最初建立在lxc容器引擎技术智商
- 后来改用自研的libcontainer,并且与2014年开源
- 2014年,由CoreOS启动的Rocket容器项目更像是一个Docker的复刻版本
- 2016年,Docker可以原生地运行在Windows Server之上,标志着Windows容器的出现
Docker基本介绍
这个章节将会为你讲述关于docker的架构对比传统虚拟化又有什么优势,以及安装和配置docker。
容器的介绍
为什么现在容器现在这么流行我认为有几个点是非常重要的,我们可以先看一下这张图:
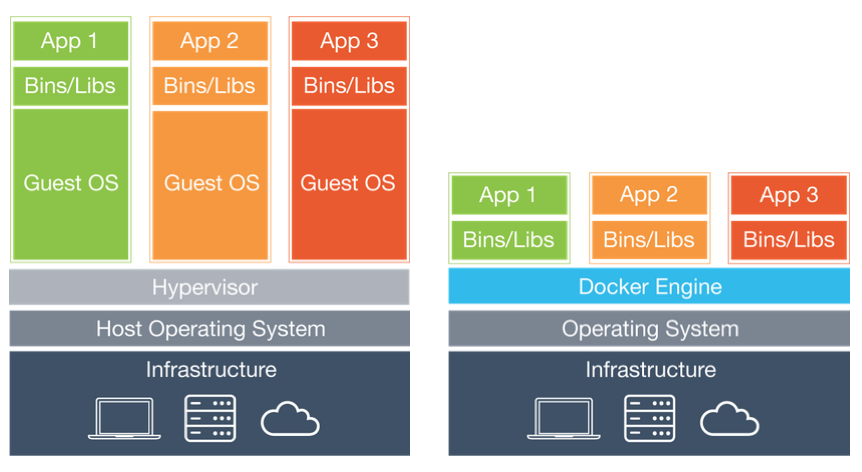
在这张图中我们可以看到像是传统的虚拟化需要宿主机上有一层Hypervisor,再在这层上去创建虚拟机和安装系统。这个成本相对来说是很高的同样也带来了不是很灵活的特点。
而docker的话少了Hypervisor这一层,使用容器镜像的方式去运行APP,这个容器镜像只包含了运行必要程序以及需要的库文件,共享宿主机的内核。这样看来使用的资源就相对来说少了很多,同时也更加的灵活。
docker相比较于传统的虚拟化使用的是使用的是内核的cgroups+namespace的技术实现的抽象成本比较低,而且也比较的灵活。
接下来为了能够更好的理解docker我们来看看docker的架构图:

在这个图里面,我们可以使用clinet对docker daemon发出指令让其执行对应的操作。实际上去实现管理容器(创建、删除、停止、启动)这些操作的底层,就叫做runtime,我们现在学习的docker其实也是一种runtime,只不过是相对来说是比较高级的runtime。与之类似的还有:containerd….。这些runtime除了本身对容器的管理之外还实现了对镜像的管理。 除了讲到的这些比较高级的runtime,实际上还有一些比较低级的runtime比如说:runc、gvisor、lxc、kata。实际上高级别的runtime在实现容器管理的时候也会去调用低级别的runtime。
这里面有几个重要的概念:
- Docker images (打包的用户空间和用到的应用程序以及相关依赖)
- Docker Container (运行的容器)
- Dockerfile (标准化了交付环境)
- dockerd和docker cli (docker的守护进程和docker的客户端)
Dockerfile标准化了交付环境
FROM: 定义标准化环境,比如说是这个镜像使用的alpine还是centos操作系统作为运行时的系统环境RUN: 初始化脚本VOLUME: 数据存储CMD和ENTRYPOINT: 启动命令EXPOSE:服务端口
dockerfile是如何标准化了交付环境?
首先我们可以暂时抛开dockerfile这个概念,可以把它想像成一个黑盒。这个黑盒提供了一些简单的监控接口(健康监测)还有钩子(hook)事件处理的接口,这些对于我们理解云原生的概念来说是至关重要的。
编排模板标准化交付内容与拓扑
在实际的应用场景中微服务可能依赖于其他的服务或者是中间件,这个时候就需要用到容器编排的技术,通过容器编排来去提供微服务的依赖服务。
docker提供了docker-compose这样的编排工具,这个工具标准化了交付内容和拓扑,像是以下基本的内容都可以去定义:
- db和wp:应用名称
- image:交付的最小单元
- environment和env_file: 应用配置
- links: 应用之间的关系
- restart: 应用重启策略
OCI与容器运行时
关于docker镜像
- Docker镜像包含有启动容器所需要的文件系统及其内容,因此,其用于创建并启动docker容器
- 采用分层构建机制,最为底层的为bootfs,在网上一层就是rootfs
- bootfs:位于系统引导的文件系统,其中包括了bootload和kernel,容器启动完成之后会被卸载以节约内容开销
- rootfs:位于bootfs之上,表现为docker容器的根文件系统
- 传统模式下,系统启动的时候,内核挂载rootfs首先会将其挂载为“只读”模式,完整性检查通过之后才会将其重新挂载为读写模式
- docker中,rootfs由内核挂载为“只读”模式,而后通过“联合挂载”技术额外挂载一个“可写”层
可以参考如下图:
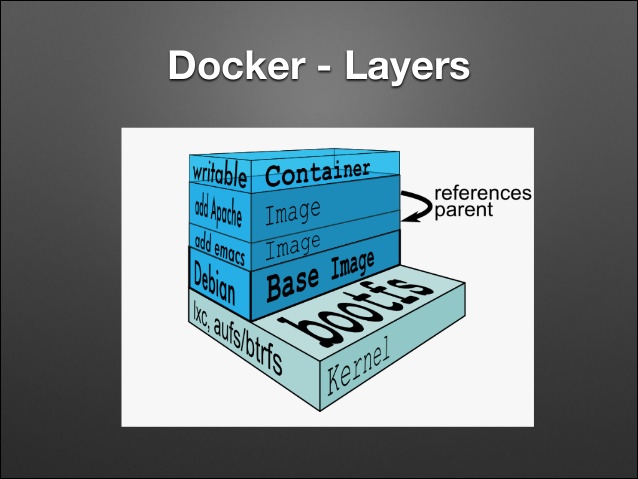
从这张图中我们可以看到的是镜像由多个只读层叠加而成的,启动容器的时候,Docker会加载只读层并且在镜像栈顶部添加一个读写层。
如果运行重的容器修改了一个现有的已经存在的文件,那该文件将会从读写层下面只读层复制到读写层,该文件的只读版本仍然存在,只是已经被读写层中的该文件副本所隐藏,这也就是“写时复制(COW)”机制。
需要注意的是如果我们想要自定义镜像的时候要确定打包机器支持相应的存储驱动,比如说overlayfs、aufs、devicemapper。
像是我们实际生产使用的时候往往需要自己去定义Registry,这个是提供了镜像的索引以及认证的服务。
再往下一层就是repository仓库,通常使用的时候每个发行版或者是服务都要给单独的一个仓库,比如说CentOS镜像。但是可以放很多个CentOS镜像比如说CentOS:1709、2009 等等
blackbox
像是我们实际去运行容器的时候,每个容器就拥有了以下的名称空间:
- MOUNT (根文件系统)
- IPC (容器之间进程通讯彼此隔离)
- NETWORK (网络彼此之间也是隔离的)
- UTS (主机名,域名)
- PID (进程)
- USER (每一个用户空间都可以有自己的用户和UID映射)
像是每个容器的资源使用情况我们可以使用CGroups去限制CPU、内存、网络等等,具体可以参考这篇文章
安装Docker
环境
在了解了docker的基本概念后,我们来安装我们的docker环境,这里我的准备了一台virtualbox的虚拟机,用于本地的安装具体信息如下表:
| hostname | ip | firewalld | selinux |
|---|
| docker-node1 | 192.168.56.30 | enable | disable |
| docker-node2 | 192.168.56.31 | enable | disable |
| docker-node3 | 192.168.56.32 | enable | disable |
这里这个虚拟机使用了2个网络:
- hostonly 192.168.56.0/24
- NAT network 10.0.2.0/24
hostonly是对外服务和管理,NAT network是能够让节点联入网络。
首先设置主机名和ip
docker-node1
1
2
3
| hostnamectl set-hostname docker-node1.nil.ml
nmcli con mod enp0s8 ipv4.method method manual ipv4.addresses 10.0.2.30/24 ipv4.dns 192.168.56.3 ipv4.gateway.10.0.2.1 connection.autoconnect yes
nmcli con mod enp0s3 ipv4.method manual ipv4.addresses 192.168.56.30/24 connection.autoconnect yes
|
docker-node2
1
2
3
| hostnamectl set-hostname docker-node2.nil.ml
nmcli con mod enp0s8 ipv4.method method manual ipv4.addresses 10.0.2.31/24 ipv4.dns 192.168.56.3 ipv4.gateway.10.0.2.1 connection.autoconnect yes
nmcli con mod enp0s3 ipv4.method manual ipv4.addresses 192.168.56.31/24 connection.autoconnect yes
|
docker-node3
1
2
3
| hostnamectl set-hostname docker-node3.nil.ml
nmcli con mod enp0s8 ipv4.method method manual ipv4.addresses 10.0.2.32/24 ipv4.dns 192.168.56.3 ipv4.gateway.10.0.2.1 connection.autoconnect yes
nmcli con mod enp0s3 ipv4.method manual ipv4.addresses 192.168.56.32/24 connection.autoconnect yes
|
修改firewalld区和更改selinux
首先我们需要更改firewalld的默认区为trusted
1
| firewall-cmd --set-default-zone=trusted
|
更改selinux
1
2
3
| sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
getenforce
|
配置yum源
这里我们要配置几个需要的yum源:
默认最小化装好是没有这些包的我们需要添加一下(为了能够加速下载的速度,这里使用清华大学的源,当然你可以根据自己的位置选择对应的镜像站):
1
2
3
4
5
6
7
8
9
| yum install wget -y
wget -O /etc/yum.repos.d/docker-ce.repo https://download.docker.com/linux/centos/docker-ce.repo
sudo sed -i 's+download.docker.com+mirrors.tuna.tsinghua.edu.cn/docker-ce+' /etc/yum.repos.d/docker-ce.repo
yum install epel-release -y
sed -e 's!^metalink=!#metalink=!g' \
-e 's!^#baseurl=!baseurl=!g' \
-e 's!//download\.fedoraproject\.org/pub!//mirrors.tuna.tsinghua.edu.cn!g' \
-e 's!http://mirrors\.tuna!https://mirrors.tuna!g' \
-i /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel-testing.repo
|
安装docker
这里我们就可以安装docker了:
1
| yum install -y docker-ce
|
将docker加入开机启动项并启动:
1
| systemctl enable docker --now
|
运行hello world
在安装完成docker之后我们可以运行一个容器来验证docker是否能够工作正常:
1
| docker run --rm hello-world
|
配置Docker加速器
在之前的hello world例子中你可能感觉速度有点慢,这个是docker的仓库在国外所以拉取镜像的时候会卡很长的一段时间,在镜像拉取完成之后运行就很快了。
为了能够有更好的使用体验,推荐配置一下docker的国内加速器,像是163,阿里云等都有提供docke让加速器,这里我们配置一下docker加速器:
1
2
3
4
5
6
7
8
| sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://56px195b.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
|
在配置完成并完成重启之后我们可以运行docker info命令来查看我们是否配置成功:
1
2
3
4
5
6
7
8
9
10
| docker info
........
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Registry Mirrors:
https://56px195b.mirror.aliyuncs.com/
Live Restore Enabled: false
|
这里可以看到Registry Mirrors这里就表示配置成功了,接下来我们可以运行一个nginx作为测试:
1
| time docker run -d -p80:80 nginx
|
用浏览器打开docker节点的ip就可以看到nginx的欢迎页面了。
Docker镜像管理
在这章节我们将会学习以下内容:
- 镜像的命名方式
- docker pull 镜像
- docker tag 镜像
- docker rmi 镜像
- docker save 镜像名 > 镜像文件.tar
- docker load -i 镜像文件.tar
docker history xx –no-trunc 可以显示完整的内容
首先是查看当前已经有的镜像:
1
2
3
4
| docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest d1165f221234 3 weeks ago 13.3kB
nginx latest f6d0b4767a6c 2 months ago 133MB
|
这里大概会有2个镜像一个是我们之前验证时候运行的hello-world和nginx镜像。
我们先来讲讲这里的镜像命名规则。
如果镜像和仓库有关系:
想要往仓库推送某个镜像
从仓库里拉取某个镜像
镜像的命名方式如下:
ip/端口/分类/镜像名:tag
比如说:
1
| example.com:5000/os/gentoo:testing
|
需要注意的是:
默认不写端口是80
分类可以从系统或者是用途考虑
镜像名称咬合力
tag不写默认是latest
重新打标签:
1
| docker tag example.com:5000/os/gentoo:testing gentoo
|
打过标签之后查看就会发现多出来一个镜像,但是这个镜像id是和我们重新打标签的id是一样的
保存镜像:
1
| docker save > nginx.tar
|
导入镜像:
1
| docker load -i nginx.tar
|
删除所有镜像脚本:
1
2
3
4
5
6
7
8
9
10
| #!/bin/bash
file=$(mktemp)
docker images | tail -n +2 | awk '{print $1":"$2}' > $file
while read aa ; do
docker rmi $aa
done < $file
rm -rf $file
|
Docker管理容器
这个章节我们来学习docker如何管理容器
启动、暂停、删除、删除
查看正在运行的容器:
查看所有的容器(包括停止和暂停状态的容器)
运行一个容器:
这个运行完成之后发现并没有什么变化,我们再去查看所有容器的状态看看:
1
2
| CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
449db807188c centos "/bin/bash" 8 seconds ago Exited (0) 7 seconds ago exciting_rhodes
|
为什么我们创建出来的容器怎么就直接退出了呢?
这个就涉及到了容器的生命周期问题,当进程不存在的时候容器就退出了。像是我们运行的centos这个容器默认的是一个/bin/bash的command,像是/bin/bash我们运行的时候并没有与之交互也没用传递参数给到这个容器,所以在/bin/bash运行完成之后容器就已经退出了。
现在我们删除这个已经停止掉的容器:
我们重新运行这个centos容器,这次我们要添加2个参数用于和这个容器前台交互:
1
2
| docker run -it centos
[root@ef09f8bb15dd /]#
|
运行完成之后给我们返回了一个交互式的shell,当我们退出这个容器之后就可以看到容器的状态已经是停止了的:
1
2
3
4
| exit
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ef09f8bb15dd centos "/bin/bash" About a minute ago Exited (130) 1 second ago jovial_merkle
|
我们还可以将这个退出的容器重新运行起来:
1
| docker start ef09f8bb15dd
|
那么这个时候如果我们想要进入这个容器应该怎么进入的呢?
我们可以使用attach这个命令来去链接:
1
| docker attach ef09f8bb15dd
|
现在我们来总结一下在上面的这个例子中的问题:
- 使用容器很费力,每次都需要找到容器的ID
- 一旦创建好容器之后,会自动的进入容器
- 一旦退出了容器,容器就会关闭
我们一个一个来解决这些问题:
- 针对于这个问题我们可以给容器一个名字作为标识,比如说:
1
| docker run --name=demo centos
|
这样子我们就有了一个名字为demo的容器运行着centos的镜像。
- 针对与这个问题我们可以更改创建时候的参数,使用
docker run --help查看了一下帮助手册发现了-d这个选项这个选项的意思是:在后台运行容器并打印容器ID。我们可以这样写创建centos容器的命令:
- 针对这个问题可以设置重启策略,比如说:
1
| docker run --restart=always centos
|
这样子每当我们退出容器的时候,容器停止运行然后会被自动重启。
那么我们结合一下这些参数命令为:
1
| docker run --name=demo -itd --restart=always centos
|
查看一下正在运行的容器:
1
2
3
| docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ba0e50a08ca7 centos "/bin/bash" 2 seconds ago Up 1 second demo
|
这样子我们就创建了一个名字为demo的容器使用centos镜像运行着一个/bin/bash的进程。
现在我们再来测试一下之前的实验。
首先进入容器:
然后退出容器并查看容器的状态:
1
2
3
4
| exit
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ba0e50a08ca7 centos "/bin/bash" 3 minutes ago Up 3 seconds demo
|
这里看到状态的部分在3秒之前启动,说明我们的容器在退出之后又重新启动了一次。
现在来让我们删除这个容器:
1
2
| docker rm demo
Error response from daemon: You cannot remove a running container ba0e50a08ca7d3085a45c6edcd772b7ba1eded7d2ee32971e3a88c1e70dbba59. Stop the container before attempting removal or force remove
|
这里报错了,提示说要我们先要停止掉这个容器然后再去删除这个容器。
如果不想先停止容器然后再去删除的话可以这样子:
这样就强制删除了。
我们再来思考一个问题,在刚刚的例子当中我们使用的centos镜像所创建的容器运行的命令是/bin/bash那么能否运行其他的命令?
答案是:不确定。 如果镜像里面包含了我们想要运行的命令,那么就是可以被运行的,如果不包含想要运行的命令那么就会创建失败。
我们来运行两个例子来看看:
运行一个sleep命令
1
2
3
4
| docker run --name=demo -itd --restart=always centos sleep 100s
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0871448b8701 centos "sleep 100s" 4 seconds ago Up 3 seconds demo
|
这里看到是被成功运行的,并且运行的不是/bin/bash了,而是sleep命令,那么我们再来找一个没有的命令来试试看:
1
2
| docker run --name=test -itd --restart=always centos docker info
docker: Error response from daemon: OCI runtime create failed: container_linux.go:367: starting container process caused: exec: "docker": executable file not found in $PATH: unknown.
|
我们再来查看一下容器的状态:
1
2
3
| docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5f428425aba6 centos "docker info" About a minute ago Created test
|
因为我们给的一直重启的参数,所以这个容器始终都是在创建失败然后重新创建的状态。
有的时候我们可能会遇到这样的场景,想要给容器内传输一些变量(比如说给到一个服务注册的地址)这个时候应该怎么做呢?
docker有一个参数就是专门来做这个的,我们来运行一个例子来看看:
1
2
3
| docker run --name=c1 -it -e demo=1 centos
e[root@026caf0470de /]# echo $demo
1
|
这里可以看到让我们创建完成容器之后去输出这个变量demo其返回值就是我们当初给到这个容器的值。
我们可以来看看容器内的变量时什么样子的:
1
2
3
4
5
6
7
8
9
10
11
| [root@026caf0470de /]# printenv
LANG=en_US.UTF-8
HOSTNAME=026caf0470de
demo=1
PWD=/
HOME=/root
TERM=xterm
SHLVL=1
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
LESSOPEN=||/usr/bin/lesspipe.sh %s
_=/usr/bin/printenv
|
这里可以看到的是在环境变量中有demo=1这个变量。
退出容器再去查看这个容器的详细信息:
我们关注一下输出中的Env字段:
1
2
3
4
| "Env": [
"demo=1",
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
],
|
在这里也可以看到我们设置的demo=1的变量。
接下来我们来运行一个mysql的容器
首先我们拉取一个mysql的镜像:
查看一下mysql镜像的历史记录:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| docker history mysql
IMAGE CREATED CREATED BY SIZE COMMENT
c8562eaf9d81 2 months ago /bin/sh -c #(nop) CMD ["mysqld"] 0B
<missing> 2 months ago /bin/sh -c #(nop) EXPOSE 3306 33060 0B
<missing> 2 months ago /bin/sh -c #(nop) ENTRYPOINT ["docker-entry… 0B
<missing> 2 months ago /bin/sh -c ln -s usr/local/bin/docker-entryp… 34B
<missing> 2 months ago /bin/sh -c #(nop) COPY file:a209112a748b68e0… 13.1kB
<missing> 2 months ago /bin/sh -c #(nop) COPY dir:2e040acc386ebd23b… 1.12kB
<missing> 2 months ago /bin/sh -c #(nop) VOLUME [/var/lib/mysql] 0B
<missing> 2 months ago /bin/sh -c { echo mysql-community-server m… 411MB
<missing> 2 months ago /bin/sh -c echo 'deb http://repo.mysql.com/a… 55B
<missing> 2 months ago /bin/sh -c #(nop) ENV MYSQL_VERSION=8.0.23-… 0B
<missing> 2 months ago /bin/sh -c #(nop) ENV MYSQL_MAJOR=8.0 0B
<missing> 2 months ago /bin/sh -c set -ex; key='A4A9406876FCBD3C45… 2.61kB
<missing> 2 months ago /bin/sh -c apt-get update && apt-get install… 52.2MB
<missing> 2 months ago /bin/sh -c mkdir /docker-entrypoint-initdb.d 0B
<missing> 2 months ago /bin/sh -c set -eux; savedAptMark="$(apt-ma… 4.17MB
<missing> 2 months ago /bin/sh -c #(nop) ENV GOSU_VERSION=1.12 0B
<missing> 2 months ago /bin/sh -c apt-get update && apt-get install… 9.34MB
<missing> 2 months ago /bin/sh -c groupadd -r mysql && useradd -r -… 329kB
<missing> 2 months ago /bin/sh -c #(nop) CMD ["bash"] 0B
<missing> 2 months ago /bin/sh -c #(nop) ADD file:422aca8901ae3d869… 69.2MB
|
这里要说明一下的是,这个mysql镜像的mysqld进程和我们刚刚运行的centos的/bin/bash是有本质的区别的。mysqld是一个守护进程,运行起来之后就不会关闭,但是/bin/bash是运行完成之后就退出来的这点是不一样的地方。
我们现在来创建一个mysql的容器:
1
| docker run -dit --name=db --restart=always mysql
|
然后去查看容器的状态:
1
2
3
| docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d5987f81202f mysql "docker-entrypoint.s…" About a minute ago Restarting (1) 6 seconds ago db
|
这里发现这个容器一直是在重启的,这个时候我们就需要去查看容器的日志。但是容器和虚拟机不一样没有那种console接口或者是显示器这个时候应该怎么办呢?
docker实际上有个log的命令,我们通过这个来看看容器究竟是发生了什么:
1
2
3
4
5
6
| docker logs db
2021-04-03 17:54:47+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.23-1debian10 started.
2021-04-03 17:54:47+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql'
2021-04-03 17:54:47+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.23-1debian10 started.
2021-04-03 17:54:47+00:00 [ERROR] [Entrypoint]: Database is uninitialized and password option is not specified
You need to specify one of MYSQL_ROOT_PASSWORD, MYSQL_ALLOW_EMPTY_PASSWORD and MYSQL_RANDOM_ROOT_PASSWORD
|
这里提示我们必须要给mysql设置一个密码,还记得我们之前是怎么给容器设置变量的吗?我们这次就是通过-e设置变量给到容器。
首先删除容器:
重新创建mysql容器:
1
| docker run -dit --name=db --restart=always -e MYSQL_ROOT_PASSWORD=p@ssw0rd! mysql
|
查看容器的状态:
1
2
3
| docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ffeb7518206b mysql "docker-entrypoint.s…" 8 minutes ago Up 8 minutes 3306/tcp, 33060/tcp db
|
这个时候我们看到这个容器已经启动起来了~
那么这里还有一个细节需要思考一下,容器里面运行的进程宿主机里面是否可以看到呢?
我们来查看一下宿主机上能不能看到mysqld的进程:
1
2
3
4
| ps -eauxf
.......
root 6033 0.0 0.4 113364 4272 ? Sl 01:59 0:00 /usr/bin/containerd-shim-runc-v2 -namespace moby -id ffeb7518206b466234b52e3cca839883badc781fccc360ffcc17cd477114fd3e -addre
polkitd 6053 0.4 33.8 1272000 343236 pts/0 Ssl+ 01:59 0:02 \_ mysqld
|
答案是可以看到的和虚拟机不一样,虚拟机是可以做到进程的隔离的。
现在假设一下有个场景,我们需要进入到这个mysql的容器里面我们可以像之前那样进入这个容器吗?
如果像是我们之前的attach命令那么就是进入到了/bin/bash命令中,我们如果是attach这个mysql容器那么就是mysqld命令。这个是没有办法正常交互的啊,这个时候就需要另外的一个命令了exec这个就是额外打开一个/bin/bash的进程。
让我们来看一个例子:
1
2
| docker exec -it db /bin/bash
root@ffeb7518206b:/#
|
我们可以登陆一个新的终端来查看一下这个db的容器都有哪些进程:
1
2
3
4
| docker top db
UID PID PPID C STIME TTY TIME CMD
polkitd 6053 6033 0 01:59 pts/0 00:00:03 mysqld
root 6469 6033 0 02:15 pts/1 00:00:00 /bin/bash
|
这里看到除了mysqld之外还有一个/bin/bash的进程。
接下来我们来尝试运行一个nginx的容器,但是和之前的mysql容器不一样的地方是我们想让其他的节点也能够访问这个nginx容器。
这里我们就涉及到了一些网络的问题了,不过在这个章节我们不会过多的讲述网络的内容,网络会有专门的一个章节来讲述,我们来运行一下这个nginx容器:
1
| docker run -dit --name=web -p 80 nginx
|
我们来查看一下容器的状态:
1
2
3
| docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
54fd07690e1f nginx "/docker-entrypoint.…" 2 seconds ago Up 1 second 0.0.0.0:49153->80/tcp web
|
在端口的地方我们看到来2个端口一个是49153和80我们首先指定的那个80其实是容器的端口,49153是在宿主机上随机映射的。
访问这个节点+端口就可以看到nginx的欢迎界面了:
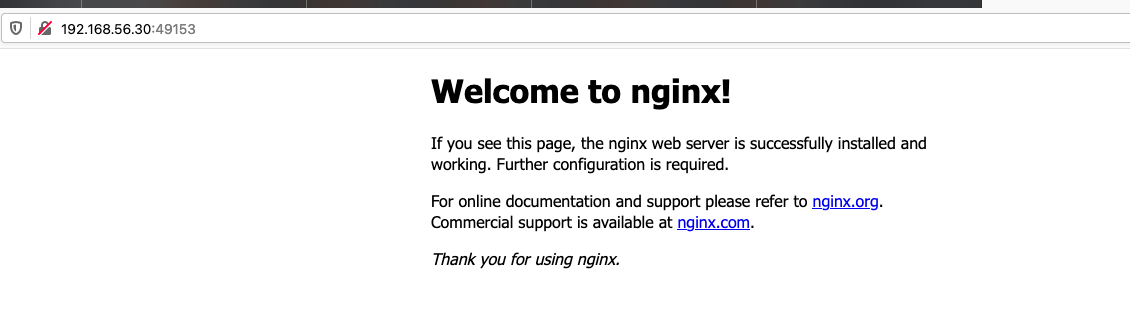
像是我们正常的去访问网站我们一般都是输入一个域名是不需要再去输入端口的,那么我们如何去指定这个端口呢?
首先删除容器:
创建容器:
1
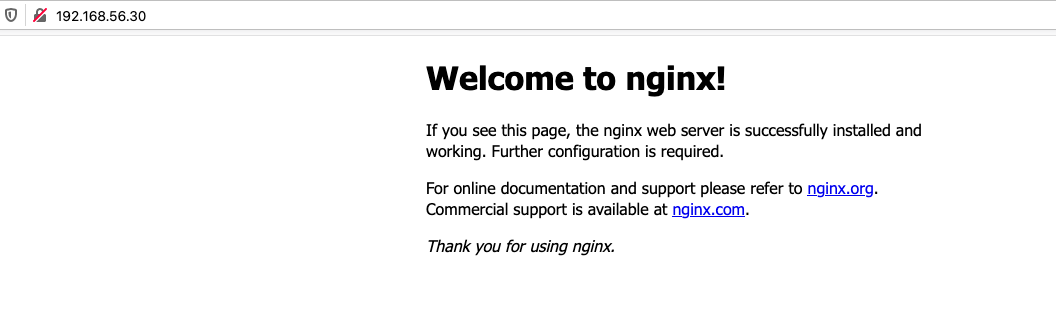
| docker run -dit --name=web -p 80:80 nginx
|
冒号左边是宿主机的端口,右边是容器的。
我们现在再去查看一下容器:
1
2
3
| docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b103ee75da33 nginx "/docker-entrypoint.…" About a minute ago Up About a minute 0.0.0.0:80->80/tcp web
|
这次我们直接通过IP访问:
有的时候我们会运行一些测试容器,想要运行完成之后就直接把这个容器删除掉可以使用一个--rm的参数,我们来试试看:
1
2
3
4
5
| docker run --rm -it centos /bin/bash
[root@ce4da6691ad1 /]# echo 111
111
[root@ce4da6691ad1 /]# exit
exit
|
查看容器:
1
2
3
4
| docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b103ee75da33 nginx "/docker-entrypoint.…" 6 minutes ago Up 6 minutes 0.0.0.0:80->80/tcp web
ffeb7518206b mysql "docker-entrypoint.s…" 43 minutes ago Up 43 minutes 3306/tcp, 33060/tcp db
|
需要注意的是这个--rm参数是不能和--restart参数同时使用的
管理容器的常见命令:
- docker exec xxx
- docker start
- docker stop
- docker restart
- docker top
- docker logs -f node
- docker inspect
文件拷贝:
宿主机文件拷贝到容器:
1
2
| docker cp delete_all_images.sh db:/tmp
docker exec db ls /tmp
|
容器里面的文件拷贝到宿主机:
1
| docker cp db:/etc/hosts .
|
用scope做页面的容器展示:
1
2
3
| curl -LO git.io/scope
chmod +x scope
scope launch
|
然后打开页面http://192.168.56.30:4040/
如下图所示:
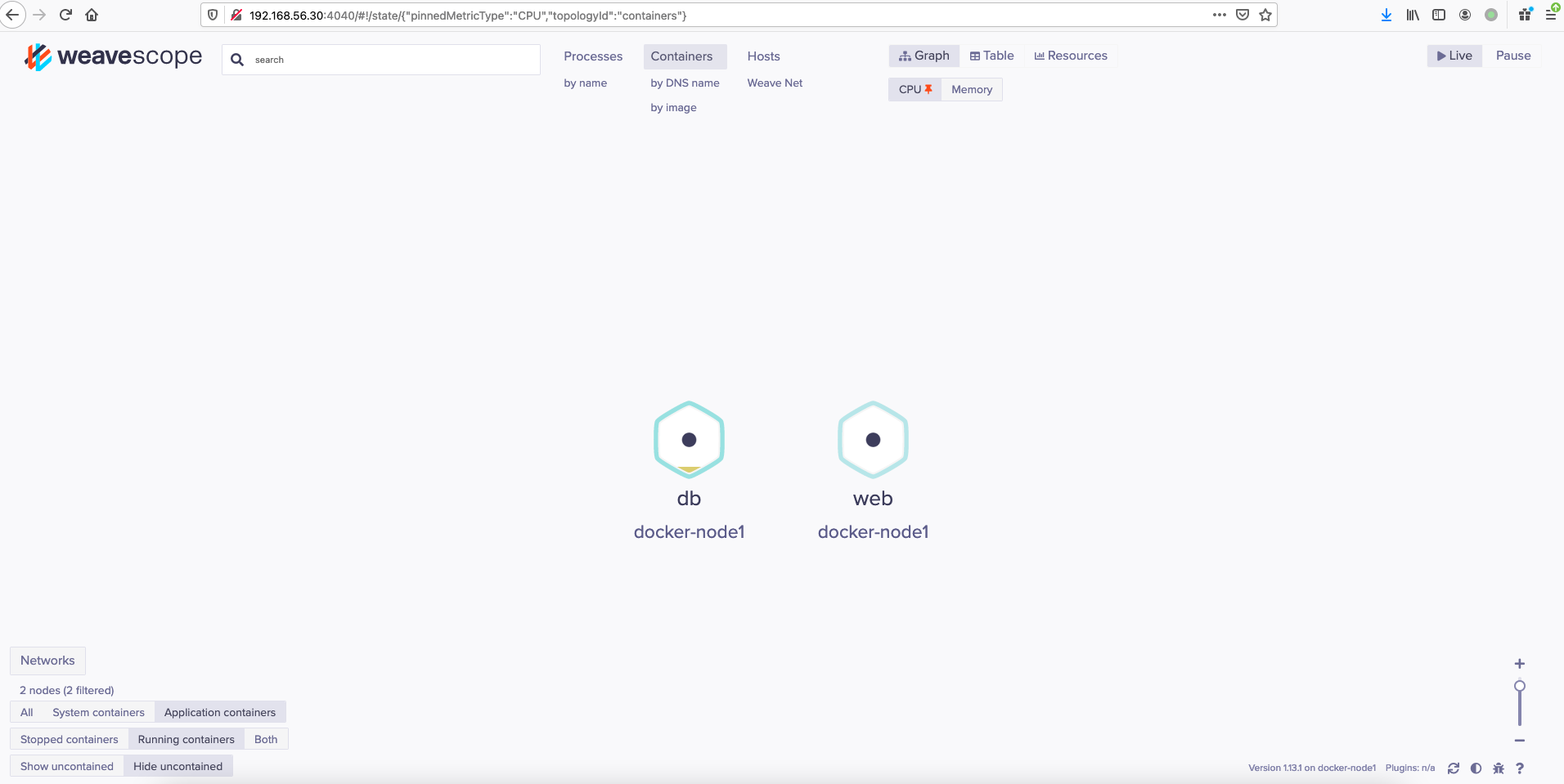
容器的权限设定
一些业务出于需求或者是安全的考虑可能需要对容器的权限进行修改,比如说管理网络的能力
,更改文件所属权限的能力,这里可以用过kernel capabilities去更改,比如说我们给容器去掉更改所属文件组的权限:
1
2
3
4
| docker run --name lab --rm -it --cap-add NET_ADMIN --cap-drop CHOWN busybox
/ # touch 111
/ # chown bin 111
chown: 111: Operation not permitted
|
--cap-add添加权限--cap-drop删除权限
这里就看到我们去更改111文件所属权限的时候就没办法去更改了。
容器的安全计算模式
安全计算模式通常缩写为seccomp,用于限制用户对系统调用的访问,相比较于kernel capabilities更加详细和精密,这部分的内容比较多,我计划是放在之后的CKS部分的文章当中。
这里不去做过多的介绍。
Docker数据卷使用
这个章节我们主要是了解数据卷的使用。
我们在容器内创建的文件实际上是会映射到宿主机上面去的:

我们来实际做一个实验试试看:
1
2
3
| docker run --rm -it centos
[root@66470e5ecd76 /]# touch aa.txt
[root@66470e5ecd76 /]#
|
我们再打开一个终端来看看宿主机上面是否有这个文件:
1
2
3
| find / -name "aa.txt"
/var/lib/docker/overlay2/f1399dbbca8ffe26b6b40625f5b6f71620fae47389e500027e00ab3ccff0dfbb/diff/aa.txt
/var/lib/docker/overlay2/f1399dbbca8ffe26b6b40625f5b6f71620fae47389e500027e00ab3ccff0dfbb/merged/aa.txt
|
这里看到有2个aa.txt文件,现在我们退出这个容器然后看看这两个文件会怎样:
1
2
| exit
find / -name "aa.txt"
|
当我们退出这个容器之后容器被删除了对应的我们在容器内创建的文件也一起被删除了。
我们思考一下在实际场景下,比如说运行一个nginx容器访问的请求过来了之后会被写在容器的文件系统里面,当我们删除这个容器的时候相对应的访问日志也一并被删除了。我们肯定不希望这样子,那么有没有一种方法可以让这些数据持久保存呢?
当然有这一章的数据卷就是可以帮我们达成这个目的。
这里我们来创建一个centos的容器来看看如何实现数据卷的挂载以及权限的控制。
首先是在宿主机上创建一个数据卷
创建容器:
1
| docker run --rm -it -v ~/demo:/demo centos
|
冒号左边的是宿主机的目录,右边的是容器的目录,即使不存在也会被创建。
我们来生成一个测试文件:
1
| echo demo > /demo/1.txt
|
然后退出容器查看宿主机上是否有这个1.txt
1
2
3
| exit
cat demo/1.txt
demo
|
接下来我们再去创建一个容器,这次呢挂载的权限要设置一下,这次想要实现只读的权限:
1
| docker run --rm -it -v ~/demo:/demo:ro centos
|
我们尝试去写一下文件:
1
2
| echo 111 > /demo/2.txt
bash: /demo/2.txt: Read-only file system
|
这里就提示了这个是只读的文件系统没办法让我们去写入。
实际的数据持久化中需要根据实际的业务场景需要来设定,比如说像是mysql的/var/lib/mysql下面才是数据存放的目录那么就需要将这个目录挂载到宿主机的一个目录上。
Docker网络
Docker网络这个章节是稍微有点复杂的章节,这个章节可能需要花费点时间好好看看。
我们先来看看Docker内置支持的4中网络类型
- None
- Bridge
- Overlay
- Underlay
为了能够更好的理解Docker的网络我们可以参考这张图:

像是我们创建虚拟机的时候一般来说都会创建一对 veth设备: a pair
一个链接到交换机上,一个链接到容器上这个交换机就是bridge交换机。
在我们安装并启动docker之后docker就自动创建了以下几个网络设备:
1
2
3
4
5
| docker network list
NETWORK ID NAME DRIVER SCOPE
45a82ca52204 bridge bridge local
c936ca3fb150 host host local
c089ad8a6a6a none null local
|
像是刚刚说的bridge设备其实我们再注意看上面的图,就会发现这个实际上会链接到一个docker网桥的,我们去机器上看看是不是有这个网桥设备:
1
2
3
4
5
6
7
8
9
| ip addr show
.....
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:e7:af:d2:3c brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:e7ff:feaf:d23c/64 scope link
valid_lft forever preferred_lft forever
....
|
这里可以看到是有一个docker0的网络设备这个网络地址是 172.17.0.1/16的网络。
像是我们之前运行的nginx和mysql容器默认就是运行在bridge的网络下面。
如果想要手动指定可以运行:
1
| docker run -it --name demo1 --net bridge busybox /bin/sh
|
然后可以使用inspect去查看详细的ip信息
1
| docker inspect demo1 |grep IPAddress
|
像是这样运行的时候并不是跨主机的,也就是容器的服务只能在本地使用,像是换一个主机就不能够正常的去访问了,在之前的nginx实验中我们使用了-p的参数这个参数实际上就是帮我们做了DNAT端口映射。
1
2
3
| iptables -t nat -vnL|grep 80
0 0 MASQUERADE tcp -- * * 172.17.0.3 172.17.0.3 tcp dpt:80
0 0 DNAT tcp -- !docker0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:80 to:172.17.0.3:80
|
这里可以看到就是做了一条DNAT规则
网络的创建和删除
这里我们创建一个自定义的网络
1
| docker network create -d bridge --subnet 10.10.0.0/24 mynet
|
创建成功后我们来查看一下:
1
| docker network inspect mynet
|
我们来看一下输出的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| [
{
"Name": "mynet",
"Id": "e74e94baadc4abdb1faba9d5347be2afe92b72cb31760da427ba4958e1daa12d",
"Created": "2021-04-05T07:49:29.354166377+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "10.10.0.0/24"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
|
这里面的subnet就是们之前配置过的,还有类型是bridge,同时我们可以查看一下宿主机的网络接口是不是多了一个网络接口:
1
2
3
4
5
6
| ip addr show
.....
119: br-e74e94baadc4: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:25:58:fb:e5 brd ff:ff:ff:ff:ff:ff
inet 10.10.0.1/24 brd 10.10.0.255 scope global br-e74e94baadc4
valid_lft forever preferred_lft forever
|
这里看到这里创建了一个网桥这个就是我们刚刚创建的那个网络。
如果删除的话就可以直接运行:
1
| docker network rm mynet
|
这样网络就会被删除掉了。
容器互通测试
像是实际使用当中微服务往往都是需要多个组件和服务才能够正常运行起来,这里我们通过一个简单的测试来看看如何实现网络的互通。
这次我们使用的是bridge网络,创建2个busybox容器进行互ping测试。
创建busybox1:
1
| docker run -it --rm --name busybox1 busybox
|
创建busybox2:
1
| docker run -it --rm --name busybox2 busybox
|
查看busybox1的ip:
1
2
3
4
5
6
7
8
9
| / # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
120: eth0@if121: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
|
使用busybox2进行测试:
1
2
3
4
| / # ping -c2 172.17.0.4
PING 172.17.0.4 (172.17.0.4): 56 data bytes
64 bytes from 172.17.0.4: seq=0 ttl=64 time=0.155 ms
64 bytes from 172.17.0.4: seq=1 ttl=64 time=0.112 ms
|
这里可以看到在同一个网络下面网络是可以通讯的,在实际的生产中也要注意这个网络规划。
Docker自定义镜像
这个章节我们将会了解一下如何自定义Docker自定义镜像。
Docker镜像并不是从0到1的过程,而是在一个存在的镜像的基础上,进行构建出来新的镜像。
最底层是一个干净的系统一般是由厂商来提供
Docker镜像实现了标准化交付的结果,我们想要自己去做Docker镜像的话就需要去了解一下Dockerfile的语法。
Dockerfile的语法很简单,格式只有2种:
#开头的就是注释- Docker指定的参数(像是FROM、RUN、CMD之类的)
在我们编写完成Dockerfile之后就需要用到一个工具来进行构建docker build,FROM一般是一个已经做好的镜像比如说centos、ubuntu之类的,不会从源头开始做镜像。RUN这层必须是FROM镜像中包含的命令,比如说指定了CentOS的镜像那么运行apt肯定是会构建失败的。
执行命令 (RUN)
在这一层运行的命令,比如说我们使用CentOS作为基础镜像然后安装一个net-tools的包:
1
2
| FROM centos
RUN yum install net-tools -y
|
在临时容器里就会在这一层安装一个net-tools的包
拷贝文件 (ADD)
在这一层运行的命令是ADD,这个命令会将我们指定的文件从宿主机拷贝到容器中去:
1
2
3
| FROM centos
RUN yum install net-tools -y
ADD <src> <dest>
|
和ADD这个命令类似的还有一个COPY的命令,ADD命令针对于压缩包会自动解压,而COPY命令只是单独的拷贝。
卷 (VOLUME)
这个命令是在容器定义一个卷,我们可以配置运行程序的目录为一个卷,方便后续的数据持久化。
这个卷在启动容器后会挂载到docker数据目录下,也可以通过 -v参数来手动指定。
运行命令 (CMD)
容器最终运行的守护进程,比如说:
1
2
3
4
5
| FROM centos
RUN yum install net-tools -y
ADD <src> <dest>
CMD ["/bin/bash"]
|
这里我们运行的守护进程就是/bin/bash
变量 (ENV)
在Dockerfile声明一下变量,就像是我们之前运行mysql容器那样给容器内的应用传递变量,一般这个可以用于初始化应用来使用,后面创建容器的时候也可以添加变量来使用。
.dockerignore 文件
这个文件就是告诉docker什么文件可以忽略掉,不用打包或者是复制。
比较实际的一个场景是当我们给容器复制整个目录的时候这个文件可以过滤掉我们不想要复制的文件。
练习
我们以alpine为基础镜像并在这个镜像里面部署一个nginx服务
这里我们来写一个例子(这个例子可以在我的仓库):
1
2
3
4
5
6
7
8
9
10
11
12
13
| FROM alpine
MAINTAINER <i@yafa.moe>
RUN apk add nginx --update && mkdir /run/nginx && rm -rf /var/cache/apk/*
VOLUME /var/www/html
COPY default.conf /etc/nginx/conf.d
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
|
构建镜像:
运行镜像
1
| docker run -it --rm --name demo -p80:80 demo
|
搭建私有仓库
在实际的使用场景里面可能我们的节点都是不接入互联网,或者是不想让别人获取到这个镜像的时候我们就需要自己构建docker仓库。
使用registry搭建仓库
docker官方提供里一个registry镜像,这个可以帮我们去搭建我们自己的镜像
1
| docker run -d --name registry -p5000:5000 --restart=always -v /root/vo:/var/lib/registry registry
|
其他节点配置 registry 仓库
修改默认的docker配置文件:
1
| vi /etc/docker/daemon.json
|
内容如下:
1
2
3
4
| {
"registry-mirrors": ["https://56px195b.mirror.aliyuncs.com"],
"insecure-registries": ["192.168.56.30:5000"]
}
|
保存并退出后重启docker
1
| systemctl restart docker
|
上传镜像
1
2
| docker tag demo 192.168.56.30:5000/lab/demo:v1
docker push 192.168.56.30:5000/lab/demo:v1
|
查看镜像(这里写了一个简单的脚本):
1
2
3
4
5
6
7
8
9
10
| #!/bin/bash
file=$(mktemp)
curl -s $1:5000/v2/_catalog | jq | egrep -v '\{|\}|\[|]' | awk -F\" '{print $2}' > $file
while read aa ; do
tag=($(curl -s $1:5000/v2/$aa/tags/list | jq | egrep -v '\{|\}|\[|]|name' | awk -F\" '{print $2}'))
for i in ${tag[*]} ; do
echo $1:5000/${aa}:$i
done
done < $file
rm -rf $file
|
运行容器:
1
| docker run -it --rm --name=demo -p80:80 192.168.56.30:5000/lab/demo:v1
|
使用harbor搭建私有仓库
可以在:github harbor release page这里下载最新的release文件。
1
2
3
| wget -c https://github.com/goharbor/harbor/releases/download/v2.1.5/harbor-offline-installer-v2.1.5.tgz
wget -c https://github.com/goharbor/harbor/releases/download/v2.1.5/harbor-offline-installer-v2.1.5.tgz.asc
gpg -v --keyserver hkps://keyserver.ubuntu.com --verify harbor-offline-installer-v2.1.5.tgz.asc
|
安装必要的包(提供了一个docker-compose编排的文件):
1
| yum install -y docker-compose
|
基于模板复制一份新的文件出来:
1
| cp harbor.yml.tmpl harbor.yml
|
修改配置文件(harbor.yml):
1
2
3
4
5
6
7
8
| hostname: 192.168.56.31
# 注释掉https
#https:
# https port for harbor, default is 443
# port: 443
# The path of cert and key files for nginx
# certificate: /your/certificate/path
# private_key: /you private_key: /your/private/key/path
|
保存并退出之后进行准备脚本:
安装:
运行完成之后用浏览器打开192.168.56.31这个地址就可以看到harbor的登录页面了:
 默认的密码可以在我们之前修改的compose文件中找到:
默认的密码可以在我们之前修改的compose文件中找到:
1
2
| grep harbor_admin_password harbor.yml
harbor_admin_password: Harbor12345
|
默认的用户为admin。
接下来我们来模拟一下类似于Docker hub的体验。
创建一个公开的lab项目:
首先点击创建项目:
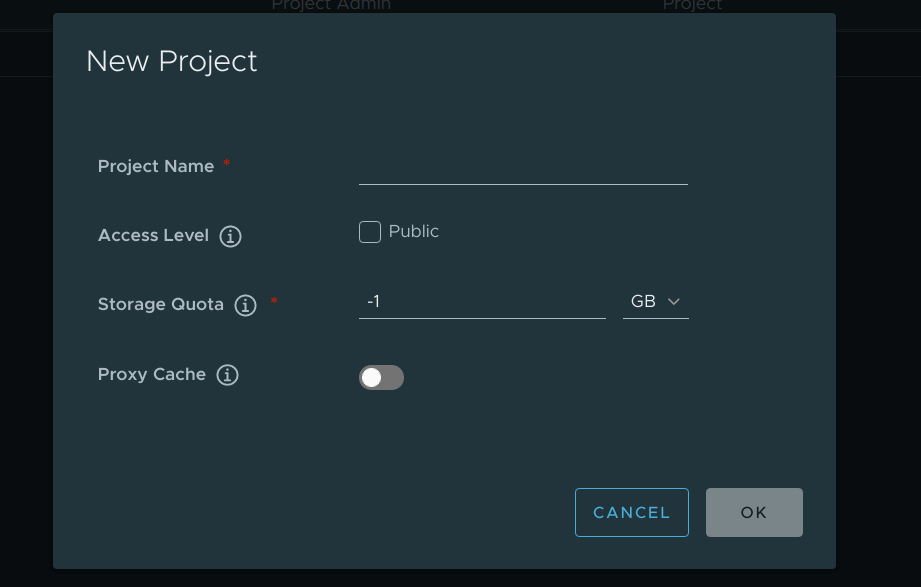
名字我们这里就叫lab
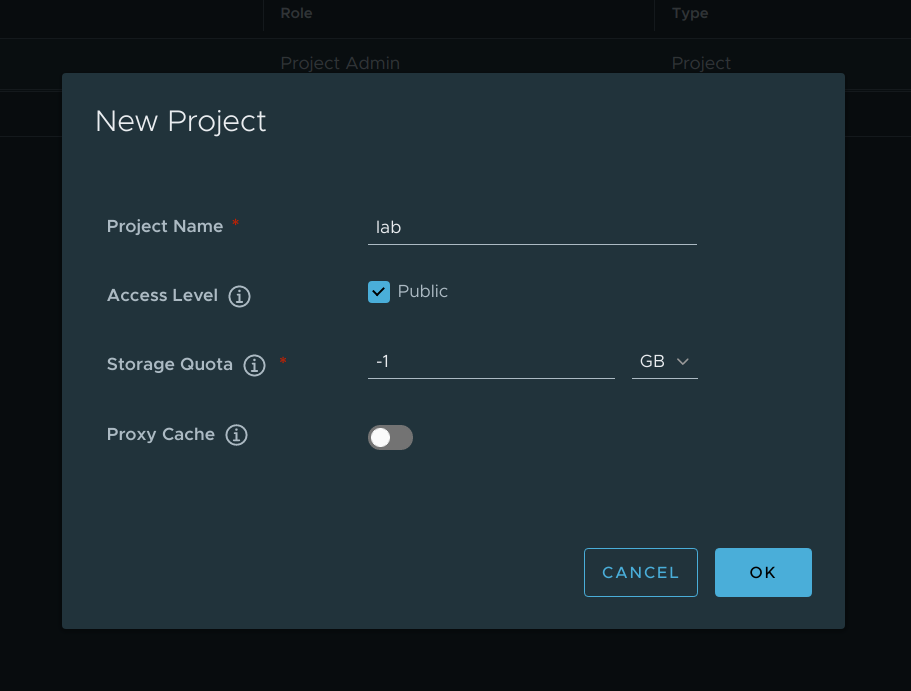
创建完成之后我们来看一下最终的结果:
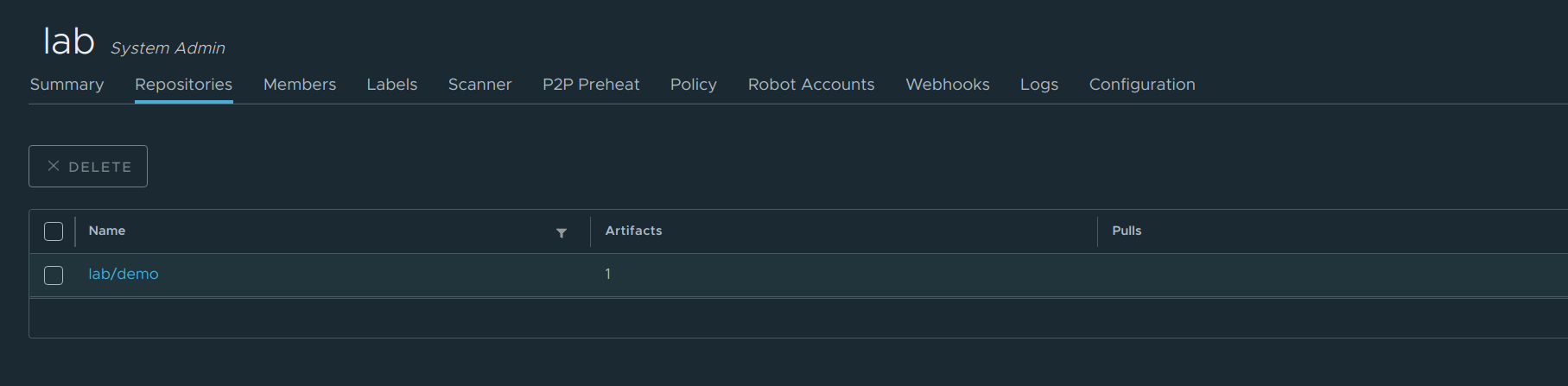
除此之外我们还需要创建一个用户,使用这个全新的用户去管理这个仓库:
接下来在我们创建的这个yafa用户给到对应的权限:
这里我们的lab仓库就已经创建好了,接下里我们来修改一下我们的docker配置文件,让其指向我们创建的harbor地址。
修改docker的配置文件:
1
2
3
4
5
6
7
8
9
| {
"registry-mirrors": ["https://56px195b.mirror.aliyuncs.com"],
"insecure-registries": ["192.168.56.31:80"]
}
重启docker:
```shell
systemctl restart docker
|
使用我们创建的用户登录到harbor:
1
| docker login 192.168.56.31:80
|
上传镜像,这里我们以之前创建的demo镜像为例子进行测试;
1
2
| docker tag demo 192.168.56.31:80/lab/demo:v1
docker push 192.168.56.31:80/lab/demo:v1
|
限制系统资源
在这个章节里主要是如何限制容器在运行时候的资源。
在开头我们有讲到Docker实际上就是使用namespace+cgroups去实现的一个runtime,这里说到的限制资源实际上也就是使用cgroups进行限制。
为什么要做限制呢?
可以设想一下这样的一个场景,容器内运行了mysql+http的服务,每个服务都以为自己是唯一的进程相应的需要的资源竞争理论上应该是不存在的,但是在之前的namespace介绍种我们知道容器是通过namespace的技术做进程的隔离的,但是在操作系统看来容器的进程和宿主机运行的其他进程是一样的,也就是说容器内运行的进程还是要和宿主机的其他进程进行资源的竞争,为了解决这部分的问题容器引入了另外的一个技术也就是cgroup。
在Linux系统中cgroup给用户暴露出来的接口是文件系统,它以文件和目录的方式在操作系统的/sys/fs/cgroup路径下,我们可以使用mount命令进行查看:
这部分是我在Gentoo系统下的输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| mount -t cgroup
openrc on /sys/fs/cgroup/openrc type cgroup (rw,nosuid,nodev,noexec,relatime,release_agent=/lib/rc/sh/cgroup-release-agent.sh,name=openrc)
cpuset on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cpu on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
cpuacct on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
blkio on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
memory on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
devices on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
freezer on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
net_cls on /sys/fs/cgroup/net_cls type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls)
perf_event on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
net_prio on /sys/fs/cgroup/net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio)
hugetlb on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
pids on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
rdma on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
|
这里可以看到在/sys/fs/cgroup目录下有很多的目录像是cpuset,blkid,memory这样的子目录,这些目录也叫做子系统。
这些都是在当前运行的操作系统下可以被Cgroups进行限制的资源种类。
我们在看看这些子系统的文件夹下包括什么:
1
2
3
| ls /sys/fs/cgroup/cpu
cgroup.clone_children cgroup.sane_behavior cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat release_agent
cgroup.procs cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release tasks
|
这里的输出就是cpu子系统的配置文件,比如说cpu.cfs_quota_us,cpu.rt_period_us这些关键字。
这些参数可以组合使用来限制进程所能够分配的资源。
我们这里来做一个简单的实验,是打算限制一个进程能使用到的cpu带宽。
为了实现这个目的我们要使用到的是cpu的子系统我们可以在/sys/fs/cgroup/cpu/下创建一个名叫container的目录
1
2
| mkdir -pv /sys/fs/cgroup/cpu/container
ls /sys/fs/cgroup/cpu/container
|
我们来执行这么一条死循环的脚本:
1
| while : ; do : ; done &
|
使用top工具来看cpu的使用率
1
| %Cpu(s): 99.7 us, 0.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
更改进程只能使用20ms的cpu时间也就是在这个子系统下的进程只能用到20%的cpu带宽:
tips: 20000 的单位是us
1
| echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
|
查看pid
1
2
3
4
5
| jobs -l
[1]+ 1348 Running while :; do
:;
done &
|
将pid放到我们创建的container子系统中:
1
| echo 1348 > /sys/fs/cgroup/cpu/container/tasks
|
这里可以看到负载已经降下来了:
1
| %Cpu(s): 19.5 us, 0.0 sy, 0.0 ni, 80.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
除了cpu子系统之外,cgroups的每一个子系统都有其独有的资源限制能力,比如说常用到的:
blkio为块设备限制I/O,一般用于磁盘等设备。cpuset 为进程分配单独的CPU core和对应的内存节点。memory 为进程设定内存使用的限制
除了这里列举的这些还有更多可以参考官方的内核文档
除了手动添加task到对应的子系统我们还可以通过systemd的serivces配置文件来进行配置,可以在服务中配置Service部分的字段,添加:
MemoryLimit=512M这样的内容,就可以进行限制内存,更多可以参考Redhat的Cgroups部分
对于Docker的容器而言,只需要在运行的时候加上特定的控制子系统再把这个进程的pid填写到对应的子系统的tasks文件中就可以了。
限制内存资源
首先我们来运行一个临时的容器,这里提供了一个memload的程序这个程序可以在我的Github Repo中找到。
1
| docker run -it --rm --name=demo -v /home/yafa/src/cka-courses/resources/:/resources centos /bin/bash
|
这里我们安装一个memload的程序,用于不断的消耗内存:
1
| rpm -i resources/rpm/memload-7.0-1.r29766.x86_64.rpm
|
我们这里需要再打开一个终端,来查看一下容器的资源消耗情况:
1
2
3
| docker stats demo
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
fc0e7818e555 demo 0.00% 3.922MiB / 15.53GiB 0.02% 2.22kB / 769B 0B / 0B 1
|
在这里可以看到容器默认认为自己可以分配的内存有16G,目前只占用了4MiB不到的内存,接下来我们使用memload来加大一些看看会是怎么样的。
我们这里使用memload来消耗1G的内存
这里可以看到确实已经消耗了1个G的内存:
1
2
| CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
fc0e7818e555 demo 100.96% 1.01GiB / 15.53GiB 6.50% 2.22kB / 769B 0B / 0B 2
|
我们退出容器,重新运行一个带内存限制的容器:
1
| docker run -it --rm -m 512m --name=demo -v /home/yafa/src/cka-courses/resources/:/resources centos /bin/bash
|
安装memload:
1
| rpm -i resources/rpm/memload-7.0-1.r29766.x86_64.rpm
|
同时再打开另外一个终端查看容器的资源消耗情况:
这个时候就可以看到,容器的内存限制已经被限制在512MiB内存了:
1
2
| CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
8ca47ca4903a demo 0.00% 3.332MiB / 512MiB 0.65% 440B / 413B 0B / 0B 1
|
我们可以去查看容器的进程的pid是否在对应的内存子系统中存在。
首先查看容器的pid:
1
2
| ps -ef |grep "[d]emo" |awk '{print $2 }'
8698
|
那么对应的我们可以在/proc/目录下找到对应的pid目录,查看在这个目录下cgroup文件中的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| cat /proc/8698/cgroup
14:rdma:/
13:pids:/
12:hugetlb:/
11:net_prio:/
10:perf_event:/
9:net_cls:/
8:freezer:/
7:devices:/
6:memory:/
5:blkio:/
4:cpuacct:/
3:cpu:/
2:cpuset:/
1:name=openrc:/2
0::/display-manager
|
这里可以看到有个6:memory:/这个就是内存的子系统
查看在内存子系统中是否存在:
1
| cat /sys/fs/cgroup/memory/tasks |grep 8698 && echo yes
|
或者是:
1
| cd /sys/fs/ && find * -name "*.procs" -exec grep 8698 {} /dev/null \; 2> /dev/null
|
对容器cpu的限制
这里主要设置的是cpu的亲和性
我们在系统上运行很多个任务,任务可能运行在不同的cpu上,这个是由内核的调度系统来实现的,但是遇到特定的场景的时候我们可能需要使用cpu绑定技术将特定的进程放在特定的cpu上运行从而提高性能。
首先我们运行一个临时的容器
1
| docker run -it --rm --name=demo centos /bin/bash
|
接下来我们在这个容器中运行几个cat程序:
1
2
3
4
| cat /dev/zero > /dev/null &
cat /dev/zero > /dev/null &
cat /dev/zero > /dev/null &
cat /dev/zero > /dev/null &
|
接下来我们宿主机上去查看这些cat进程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ps mo pid,comm,psr $(pgrep cat)
PID COMMAND PSR
21884 cat -
- - 2
21914 cat -
- - 1
21921 cat -
- - 3
21922 cat -
- - 2
23502 kworker/u9:1-rb -
- - 0
24129 kworker/u9:2-rb -
- - 1
|
这里看到cat进程分别运行在2 1 3 0这么4个核心上也就是说分布在每个核心上了(这台机器有4个超线程)
接下来退出容器我们选择将所有的进程运行在cpu 1上再看看有什么变化:
1
| docker run -it --rm --cpuset-cpus=1 --name=demo centos /bin/bash
|
运行cat程序
1
2
3
4
| cat /dev/zero > /dev/null &
cat /dev/zero > /dev/null &
cat /dev/zero > /dev/null &
cat /dev/zero > /dev/null &
|
现在再查看一下运行的情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| ps mo pid,comm,psr $(pgrep cat)
PID COMMAND PSR
23502 kworker/u9:1-rb -
- - 3
24129 kworker/u9:2-rb -
- - 1
26770 cat -
- - 1
26771 cat -
- - 1
26772 cat -
- - 1
26773 cat -
- - 1
|
这个时候就可以看到所有的cat进程已经运行在cpu1上面了。
监控系统资源
在日常的使用中我们的系统上面可能有着许多的容器,每个容器都是需要消耗一定的cpu内存和网络以及硬盘的存储空间,在之前的章节里面我们将讲到过可以通过docker stats这个命令来看容器的一些资源开销。
这种命令行的方式在需要查看大量的容器资源开销的时候就变得非常不方便了,那么有没有一种方法可以解决这个问题呢?
Google开源了一个叫[cadvisor](https://github.com/google/cadvisor]的工具,我们可以部署这个工具来达到监控容器资源开销的目的。
我们来创建一个cadvisor容器:
1
2
3
4
5
6
7
8
9
10
11
12
| VERSION=v0.36.0 # use the latest release version from https://github.com/google/cadvisor/releases
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--privileged \
--device=/dev/kmsg \
gcr.io/cadvisor/cadvisor:$VERSION
|
在运行之后可以使用浏览器打开对应的 ip:port ,然后就可以看到cadvisor页面:
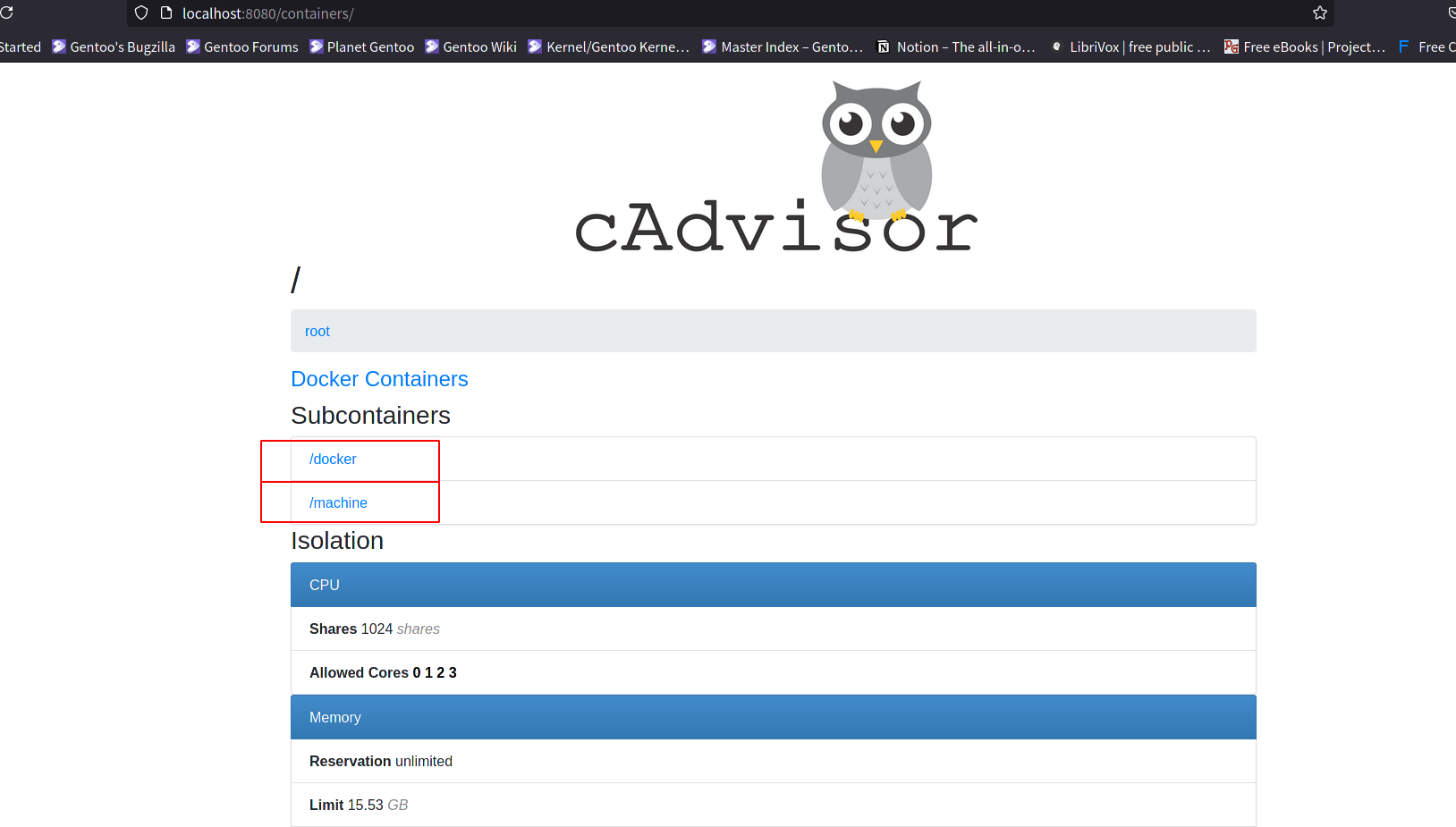
我这里用红线标注出来了正在运行的子容器信息,点击就可以进入子容器的详细信息页面,其中包括了主要的:
这个简单用起来就会发现cadvisor像较于我们在前文中介绍到的scope功能非常的简单,在实际的生产环境我们考量的点会很多,那么应该使用什么呢?
我认为可以参考这篇知乎文章来选择:滴滴云:容器领域的十大监控系统对比
结束语
终于完成这篇文章了,比我想想的要慢了许多,其中涉及到了非常多的内核相关的概念。因此花了许多时间去查阅计算机系统相关的内容和内核相关的内容,我相信有了这么一个还算是及格的基础接下来的cka部分的学习压力就会小上很多。
参考资料